


Hi! I’m Robert Neckorcuk, Platform Team Lead for ArenaNet. My team runs a number of back-end network services for the Guild Wars® franchise: log-in servers, chat servers, websites, and more. We work very closely with two other teams, Game Operations and Release Management, as the back-end services group. We also work with Gameplay, Analytics, Customer Support, and so on, but our core focus is maintaining the live state of the games and their infrastructure. The Guild Wars franchise is recognized for its impressive online availability. Although we celebrate the success of our infrastructure, we have also encountered challenges. Today I’ll be sharing the details of the last major incident and the lessons learned for us to continue improving our commitment to you.
At 6:00 a.m. Pacific Time on Monday, May 11, 2020, I got a phone call. I can assure you, I didn’t have to look up this date—it’s still a pretty vivid memory for me. Our Game Operations team had gotten a page that a live Guild Wars 2 database had rolled back, players were getting inconsistent information from the game servers, and our internal tools were displaying a slew of other related alarms and errors.
Ah, kitten.
I’ve had less exciting Mondays. In fact, I prefer less exciting Mondays. Logging on to my work machine, I joined the folks investigating both what had happened and what we could do to return the game to its normal state. For a team and company whose goal is “always online,” our investigation led to our worst fear—we would have to shut down the game to restore the data to a good state. As this was my first time with an incident like this, it took a while to identify which approvals were needed. Just after 9:00 a.m., I submitted the changes to disable the game log-ins and shut down the servers for Guild Wars 2 in our European region.
Constantly IteratingDuring this service interruption, Guild Wars 2 was down in our European data centers for just over 20 hours. Outside of a handful of minutes-long blips, the previous Guild Wars 2 shutdown happened August 23, 2016. While it is never fun to deal with live-impacting issues, we are able to use these incidents as learning opportunities to improve our infrastructure and processes. Our incident process follows that of many live-service companies, both in and outside of the games industry:
- Identify the scope of the issue—is it happening in one server, one data center, or one build? See if we can narrow our investigation to a smaller set of services or regions.
- Identify a path to get the service running as soon as possible—this is a trade-off between correctness and availability. If we get the service working by hacking something together, will we break something else?
- Once the service is running again, write up the incident report—this report should detail what happened, what informed us of the issue, what steps we took, and who was impacted.
- Later, during regular business hours, set up a meeting with key stakeholders to review the incident report and create tasks for any follow-up items—action items could be to improve alerting or detection, update documentation or automated processes, or build a new tool.
It’s not only during incidents that we look at our processes and procedures and make changes. In 2017, ArenaNet made the decision to migrate from an on-site data center to a cloud-based one, utilizing the AWS infrastructure (with zero downtime!). In 2020, after adjusting to remote work, we completed a migration of our analytics-logging pipeline from a hardware-based provider into a cloud provider.
The reason for all these cloud migrations is the offer of flexibility—we have the option to constantly change and modify our infrastructure quickly and seamlessly. In early 2020, we kicked off a holistic, internal AWS upgrade, looking at the costs and options for every server we were running, from our development commerce servers to our Live PvP scheduling servers. AWS is constantly providing new services and new hardware types, and we hadn’t performed a full audit since 2017. This planning would see us making changes to improve the player experience in the live game, matching our development environments to the live game, and improving several back-end tools. We also updated a few servers that had never changed‐or even been restarted—since our 2017 migration!
When tackling a large project, one of the most effective strategies is to break it down into smaller, more manageable chunks…like slicing up a big pizza! We wanted to go over every AWS instance, and fortunately already had several “buckets” of different instance types—game servers, database servers, commerce servers, etc. Our plan was to go through each of these one at a time, make the changes, then move on to the next group. For each set of changes, we would start by migrating our internal development servers. We’d write a runbook to document the process and verify the behavior, then migrate our staging and live environments following the runbook steps.
For any product and any company, the ability to iterate is absolutely key. Build stuff in your own backyard, bash it to pieces, break it as often and as strangely as you possibly can. Once you’ve fixed everything internally, it should be pretty resilient when it hits the public view. For the Platform and Game Operations teams, this “practice the way we play” process is yet another tool in our belt that aids our service quality. All that being said, the development and live-game servers are vastly different in terms of cost and scale, so as much as we wish everything behaved the same, they are quite unique.
Some (greatly simplified!) background on our databases: we have two servers, a primary and a secondary. When we write to the database, a message with “do this change” is sent to the primary instance. The primary then sends a message to the secondary (or mirror) with “do this change,” and then it applies the change to itself. If “bad things” happen to the primary, the secondary instance will automatically take over and report as the primary. This means there’s no downtime or loss of data, and the new primary will queue messages to send to the “new secondary” once it recovers from its “bad things.” To upgrade instances, we manually disconnect the primary and secondary databases, upgrade the secondary, and reconnect them.
One of the important data points we can track is how long it takes the secondary to receive all the queued messages from the primary and return to data parity. Combined with other load and health metrics, this can inform us whether the server is healthy or not—and I personally find graphs quite fascinating. We then swap the primary and secondary, rinse and repeat, and now we’ve got even more pretty graphs, along with a fully upgraded environment.
On the dev environment, everything ran smoothly. Our staging environment provided us another chance to run through the process end-to-end, and that also ran smoothly. We started our live-game upgrade with the European-region servers on Wednesday, May 6, 2020.
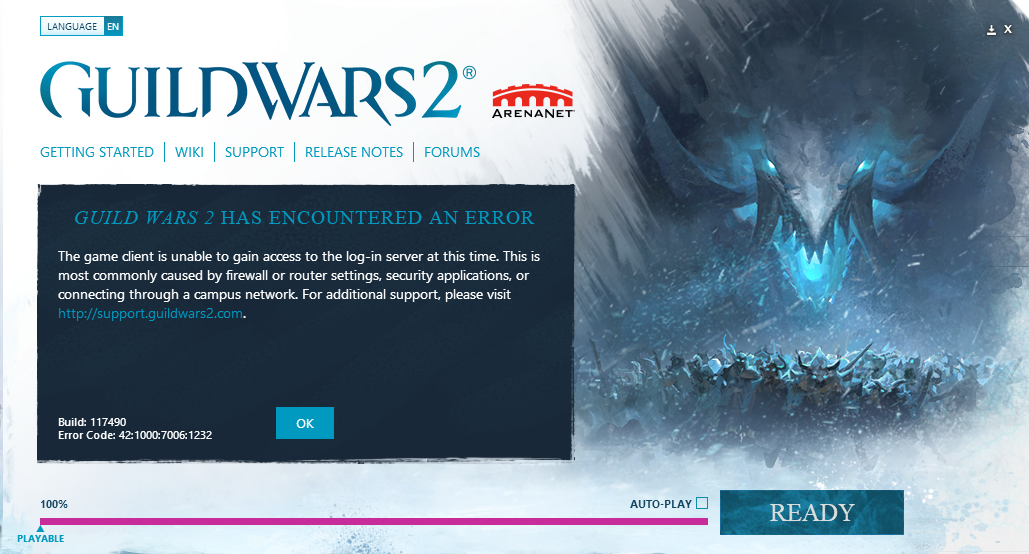
On May 6, the actual upgrade went exactly to plan. We severed the connection, upgraded the secondary, and reestablished a connection. The queued messages copied over, we swapped primary and secondary, and repeated those actions once more. The message copy was a little slower than our practice runs in the dev environment, but there was a much larger queue given the traffic volume of the live game.
Thursday, May 7, we got a “disk space almost full” alarm. We had recently made an additional backup of the data, which took up some space, but best practices dictated we expand the disk volume regardless. Storage is inexpensive, and with AWS, a few mouse clicks could double the size of our log and backup drive. A member of the Game Operations team clicked his mouse a few times, yet the expanded storage size did not magically appear. On Friday we submitted a support ticket to AWS, who recommended a restart to correct the issue. As this server was currently the primary, we would have to swap with the secondary before we could restart.
It’s very easy to look back on things and recognize the obvious mistakes, but at the time we didn’t know what we didn’t know. Friday afternoon we attempted to swap the primary and secondary so that we could perform a quick restart. At the time, however, the message queue from the primary to the secondary was not empty, and it was still copying slowly. Some calculations told us the hard drive would not completely fill up over the weekend, so we could return Monday morning, dive into the queued messages, swap the servers, and perform the restart.
We certainly returned on Monday…
While we recognized that the queued messages were sending slowly (think “turtle speed”), we failed to take into account the speed with which the queue was growing (think “jetpack turtle speed”!). Recall the somewhat accurate statement that if “bad things” happen to the primary database, the secondary will automatically take over as the new primary. As it so happens, one of the “bad things” that causes an automatic failover is this message queue growing too large.
At 2:41 a.m. on Monday, May 11, the “bad things” threshold was crossed, and the databases swapped primary and mirror. As the database update messages were all in a queue on the other server, when the databases failed over, suddenly players experienced time travel (and not the good kind) as all their progress since Friday evening was wiped away. Three painful hours later, at 5:40 a.m., our Game Operations team was called as the player reports increased. I was called at 6:00 a.m., and the game was shut down by 9:00 a.m.
As soon as the game was down, one of our first steps was to restart the primary server, and as predicted, the expanded disk volume appeared! Good news, if nothing else. On the newly expanded disk, we found the most recent automatic backup file and logs containing all the queued messages, up to 2:41 a.m.
It is excellent practice to save backups. Storage is cheap, having the option to recover data is guaranteed peace of mind, and it is very easy to schedule automated backups. Actually restoring data using that backup, however…that’s a different story, mainly because we don’t do it very often. On the one hand, there was no load on the databases, so we could tear everything down and start over if needed. On the other hand, the game was down, and we were feeling immense pressure to restore the data quickly and accurately to get the game running once again.
(Side note: I’m going to focus on the main story thread, but even at this point there were a series of side investigations around the greater impact on the Trading Post, Gem Store, new account creation, and more. A lot happened during this incident, with input from many different teams. I feel like I could write an entire book of mini stories about this one event!)
Honestly, the restore process was pretty boring, and we just followed a best-practices guide. A few button clicks in the management utility, and the server started crunching away. Before we could start, we had to copy the backup file and the log files to the second server to make sure we were restoring the same data on both. The server would then set the state of the databases to everything contained in the backup file. This process took several hours. Then it would apply all the logged messages so eventually both databases would be accurate to 2:41 a.m. This also took a long time. The first server finished at 1:37 a.m., the second at 4:30 a.m.
(Side note 2: Outside of the actual work you do, the people with whom you do work are probably the most important thing about choosing a company or a team. There were a handful of us, online since 5:30 or 6:00 a.m., taking only catnaps and otherwise working through the process into the early hours of the next day. Some server babysitting definitely happened! The ability for everyone in the war room to take the situation seriously yet manage themselves and have a bit of playfulness to get us all through the event cannot be understated. This team is amazing at what they do and how they go about doing it.)
The Guild Wars 2 infrastructure is also pretty amazing. It’s able to update with no downtime and contains many knobs and levers to turn and pull that can affect different features or content in the game for exploit prevention, crash prevention, or even changing the difficulty of dynamic events without needing a build! On May 12, we utilized another feature in the game not seen since 2016—the ability to launch live without launching live. The game would be fully online, letting developers in, but not public players.
At 4:55 a.m., we “turned on” the game, and a whole host of internal developers, QA analysts, and a handful of EU partners logged in to the game. I was hugely impressed that, within minutes, players had already identified that the game was being live tested, and their progress was restored to Monday morning. I suppose that happens when we make our APIs available!
After a smoke test of the live environment that checked the database health and the message queues, we opened up the servers to the public at 5:37 a.m., over 20 hours after shutting down. Everyone on the team was grateful to be able to help everyone get back into a world they love, myself included. I was also glad to get another few hours of sleep.
Whew.
After a few hours of rest, we all logged back in to work to try to understand what exactly was the root cause of the failure. That afternoon, an alarm triggered in our EU region—the database message-queue volume was too high.
Kitten. Again.
We had correctly identified and added a few alerting mechanisms for these newly discovered failure points. For the next two days, we manually managed the database mirroring and connections between the primary and secondary. We talked to database administrators, network operators, and our technical account managers from AWS. We configured every setting we could relating to message queues, volumes, storage, and logs. After days of reading documentation, gathering knowledge from experts, and attempting changes, we finally had our breakthrough on Friday.
Drum roll please!
The root cause was the drivers.
Drivers are what allow software operating systems to communicate with connected devices—if you have peripherals like a gaming mouse or a drawing tablet, you’ve probably downloaded specific drivers for your stuff.
In this instance, the server’s operating system did not have the latest communication method to interface with the hard drive. Not great on a database where reading and writing data to disk is 99% of its entire reason for existence… (The other 1% is the “wow” factor. Wow, you’ve got a database? Cool.)
When we upgraded the servers, we were moving from AWS’s 4th generation to their 5th generation servers, and with that came a difference in how the servers interact with connected devices (I don’t fully comprehend how the system works, but AWS has a cool name for the underlying technology: Nitro!). Our driver version was ahead of the basic version provided by AWS, so we did not expect to need additional updates. Plus, in our dev environments, this was not an issue at all! But we also didn’t have anywhere near the load there as we have on the live game. Despite it being another Friday and recognizing the consequences of an unsuccessful driver update, we decided to move forward.
As before, we severed the connection between the databases, ran the driver updates, and then reconnected.
The queue drained nigh instantly.
The data write speed measured 100,000 kilobits per second, up from the 700 Kbps we had been seeing previously.
I smiled. I laughed (somewhat uncontrollably).
We repeated the process on the other server. Again, the queue drained in a few blinks of an eye.
I slept that weekend. And I’ve had so many good Monday mornings since then.
Looking Backward and ForwardSo, that’s what actually happened, what we missed, and why the incident occurred. Next is the part that I personally love about my job: What lessons did we learn? How did we use it to grow and improve? What friends did we meet along the way?
Well, first and foremost, this was a solid reminder for us on how different the dev and live environments are. The dev environment is great for practicing, recording specific performance metrics, and more. However, for some changes, key tools like load testing and stress testing across multiple machines are still necessary.
Second, it was a reminder to always check assumptions and take a step back to look at the macro view if something is not behaving as expected. We had done our due diligence in the days before the outage, but we focused on the wrong part of the problem. Checking in with someone else would have provided us a different perspective and a need to defend the irregularity we were seeing to determine whether it could be an issue.
The most impactful change for our databases was to increase alerting on key database metrics, not just system metrics like CPU or hard drive space. For our live operations, we added a number of alerts into a third-party tool to improve our response time for future issues. And for general operations, we’ve improved the record-keeping of our AWS infrastructure, now tracking more than just the instance type. Our reports now include instance types, generation, drivers, and storage types. We built a common package to install on all new servers that includes specific driver versions. Any future migration plans will update this common package, ensuring that we don’t repeat this issue again.
We have completed the migration for all the remaining database instances and more, providing higher performance for improved service. In the last fourteen months, we’ve recorded an uptime of 99.98%, with only five minor service interruptions impacting user log-ins.
Our continued efforts are always targeted at providing you with the best experience and usability of our services. We love to celebrate the design architected by those before us and the tools and processes we utilize to retain our world-class uptime, and we are pleased to bring our current availability streak back over the one-year mark. We recognize that we may not achieve perfection, but we will certainly strive for it with every future procedure and deployment. As we look forward to the exciting new features and projects the Guild Wars 2 gameplay and design teams are bringing to you, we are constantly working behind the scenes to make sure that you can always log in and enjoy.
Wow, so, I know I can write a lot of code; apparently, I can also write a pretty long blog post. I do hope you enjoyed reading. For some, this post may be a long time in the making, but I am actually very pleased to be able to share stories like this with you. We’d love to read your thoughts and feedback about this type of post, so we’ve set up a discussion thread on our official forums!
See you online in Tyria,
Robert
View the full article


